Ultimate open vector geoprocessing on spark
 The marriage of geomesa and geospark
The marriage of geomesa and geosparkMore and more people start to work with large quantities of geospatial data and think about using spark and one of its geospatial additions like geomesa, geospark or geotrellis. And soon they come to realize that one of the tools does not provide a function which would be commonly required. In the case of geomesa, i.e. spatial joins are still a bottleneck. But there would be a nice alternative available: geospark. However, if you go all in with geospark, you have to re-invent the wheel and handcode a lot of the geospatial functions geomesa already offers ad spark-native functions.
In the following I will show you how to combine the best of both worlds.
the first step
Using your build tool of choice you need to put both dependencies on the classpath. I like to use gradle for this and add all of geomesa, geospark and their subdependencies which are required for nice SQL access to their geospatial functions.
ext {
scalaFullV = "${scalaMinorV}.$scalaPatchV"
sparkFullV = "$sparkOpenV.$sparkOpenVPatch.$hdpV"
deps = [geomesaSparkSql : "org.locationtech.geomesa:geomesa-spark-sql_${scalaMinorV}:$geomesaV",
geospark : "org.datasyslab:geospark:$geosparkV",
geosparkSql : "org.datasyslab:geospark-sql_$sparkOpenV:$geosparkV",
sparkCore : "org.apache.spark:spark-core_${scalaMinorV}:$sparkFullV",
sparkSql : "org.apache.spark:spark-sql_${scalaMinorV}:$sparkFullV",
sparkHive : "org.apache.spark:spark-hive_${scalaMinorV}:$sparkFullV",
scalaLib : "org.scala-lang:scala-library:$scalaFullV"
]
}
To be able to pull all the downloads be sure to add some additional repositories to the configuration of your build tool:
repositories {
maven { url "https://repo.locationtech.org/content/groups/releases" }
maven { url "http://repo.boundlessgeo.com/main" }
maven { url "http://download.osgeo.org/webdav/geotools" }
maven { url "http://conjars.org/repo" }
jcenter()
Then, simply add the dependencies to your project in the implementation/compile scope:
dependencies {
compile deps.geomesaSparkSql
compile deps.geospark
compile deps.geosparkSql
compileOnly deps.sparkCore
compileOnly deps.sparkSql
compileOnly deps.sparkHive
compileOnly deps.scalaLib
}
optimized serialization
By default, spark uses java serialization, which is less efficeint than a properly registered kryo serializer. So be sure to also fuse the serializer both geomesa and geospark provide in similar fashion:
val commonReg = new CommonKryoRegistrator
val geomesaReg = new GeoMesaSparkKryoRegistrator
val geosparkKryoReg = new GeoSparkKryoRegistrator
commonReg.registerClasses(kryo)
geomesaReg.registerClasses(kryo)
geosparkKryoReg.registerClasses(kryo)
// further required geo-spatial classes
kryo.register(
classOf[
scala.Array[org.datasyslab.geospark.spatialRddTool.StatCalculator]])
kryo.register(
classOf[org.datasyslab.geospark.spatialRddTool.StatCalculator])
kryo.register(Class.forName("[[B"))
As both do provide some overlapping UDF (have name clashes) it is important to register one of them with a prefix. I choose to prefix geospark UDFs as follows:
UdtRegistratorWrapper.registerAll()
Catalog.expressions.foreach(f => sparkSession.sessionState.functionRegistry.registerFunction("geospark_" + f.getClass.getSimpleName.dropRight(1), f))
Catalog.aggregateExpressions.foreach(f => sparkSession.udf.register("geospark_" + f.getClass.getSimpleName, f))
optimized spatial joins
Unfortunately, if you look at the execution plan for a spatial join:
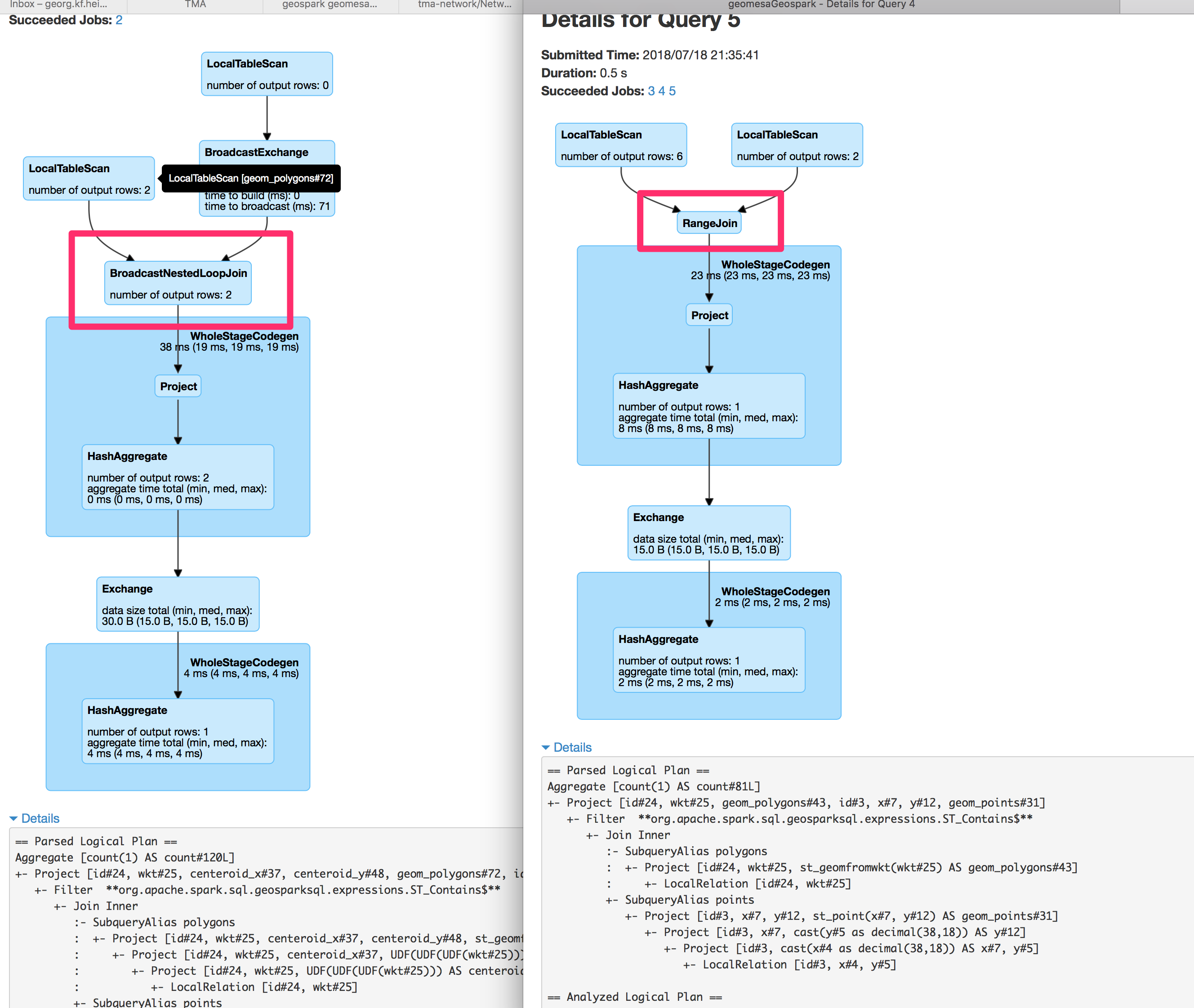
A caption
all the geospark magic seems to be lost. But it is easy to bring back efficient spatial joins:
sparkSession.experimental.extraStrategies = JoinQueryDetector :: Nil
using them both together
To use them togehter a couple of steps are needed:
// 1. use your combined kryo registrator
val spark = SparkSession
.builder()
.config(new SparkConf()
.setAppName("geomesaGeospark")
.setMaster("local[*]")
.setIfMissing("spark.serializer",
classOf[KryoSerializer].getCanonicalName)
.setIfMissing("spark.kryo.registrator",
classOf[SpatialKryoRegistrator].getName)
.getOrCreate()
// 2. register geospark functions with prefix
CustomGeosparkRegistrator.registerAll(spark)
// 3. register geomesa
spark.withJTS
// now they are all available
spark.sessionState.functionRegistry.listFunction.foreach(println)
And they can be used similarly to:
// perform some sptial computations in geomesa (these functions are not available in geospark
val polygonsEnriched = polygons
.withColumn("centeroid_x", st_x(st_centroid(st_geomFromWKT(col("wkt")))))
.withColumn("centeroid_y", st_y(st_centroid(st_geomFromWKT(col("wkt")))))
polygonsEnriched.show
// perform a spatial join, first create spatial binary geometry types using geospark functions, then join
val pointsGeom = points.withColumn("geom_points", expr(s"geospark_ST_Point(x, y)"))
pointsGeom.show
val polygonsGeom = polygonsEnriched.withColumn("geom_polygons", expr(s"geospark_ST_GeomFromWKT(wkt)"))
polygonsGeom.show
// TODO 1) how can I get rid of the textual SQL below and actually use DSL expressions? Or at least expr()? Seems only to work on map side operations as above
pointsGeom.createOrReplaceTempView("points")
polygonsGeom.createOrReplaceTempView("polygons")
val joinedDF =
spark.sql(
"""
|SELECT *
|FROM polygons, points
|WHERE geospark_ST_Contains(polygons.geom_polygons, points.geom_points)
""".stripMargin)
joinedDF.show(false)
println(joinedDF.count)
conclusion
All the code can be found here
if you like the marriage of geospark and geomesa then star the draft repository https://github.com/geoHeil/geomesa-geospark!
If you really are interested in moving the community forward help to work on the integration of Geomesa nd Geospark as a unified package so this is a more straight forward and integrated process in the future.