Local data stack template

introduction
Almost a year ago Aleks and I blogged about: the local modern data stack as a pipeline around duckdb, dagster and parquet-ish files and remote storage And 6 months later Hernan and I about scaling that concept to spark and commoditizing the data-paas.
More and more people have picked up on the idea with regards to duckdb due to the simplicity and increasing popularity of lakehouse:
- motherduck.com/blog/duckdb-enterprise-5-key-categories
- motherduck.com/blog/motherduck-dbt-pipelines
- juhache.substack.com/p/iceberg-single-node-engines
- xebia.com/blog/ducklake-a-journey-to-integrate-duckdb-with-unity-catalog
Therefore, github.com/l-mds/local-data-stack should serve as a template of how to get started with a local modern data stack. It is still a bit early, but over time it will be refined.
Usage
pixi run tpl-init-cruft
# alternatively:
cruft create cruft create git@github.com:l-mds/local-data-stack.git
cd <<your project name>>
git init
git add .
git commit -m "initial commit"
docker compose -f docker-compose.yml --profile dagster_onprem up --build
To update the template simply execute:
pixi run tpl-update
result
See for yourself: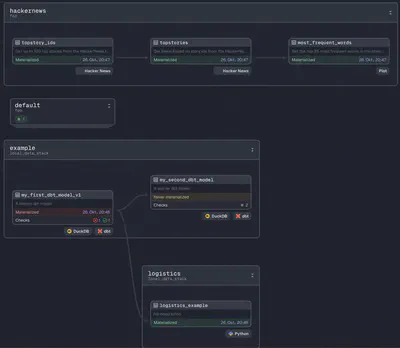
- Reproducibility
- pixi
- docker
- LMDS tools
- dagster
- dbt
- duckdb
- code quality
- pyright
- taplo
- pytest
- template updates via cruft
- secops
- age
- sops
summary
This template is a starting point to get going with a local modern data stack and waiting for more collaborative refinement.
Currently, it is still not a full reference of the duckdb blog post and lacking around partition handling and lakehouse/iceberg/delta/Hudi integration. Are you interested in contributing? Please reach out to me.
With this I wish for a world where data practitioners (albeit all the customized glue code) can build on more best practices and reference examples for their pipelines. I hope that this can serve as building blocks to speed things up and build with higher quality & confidence.