Dagster, dbt, duckdb as new local MDS

Introduction
In today’s fast-paced data landscape, a streamlined and robust data stack is paramount for any organization’s infrastructure. This article explores an integrated setup utilizing DuckDB, Dagster, and dbt - three critical tools in modern data engineering. Following the newest development in the data ecosystem, we argue that we can rethink the current state of data transformation pipelines and gain various benefits such as reduced PaaS costs, increased development experience and overall implementation quality.
Components
This data stack comprises the following elements:
- Dagster: A dynamic open-source data orchestrator designed for scalable ETL, ML, and analytics, capable of operating from a single machine to as many nodes as required.
- dbt (data build tool): Employs Jinja-style SQL templating to streamline data transformations and implement software engineering principles within analytics pipelines.
- DuckDB: A purpose-built, analytical database optimized for performance, akin to the OLAP analog of SQLite.
Architecture
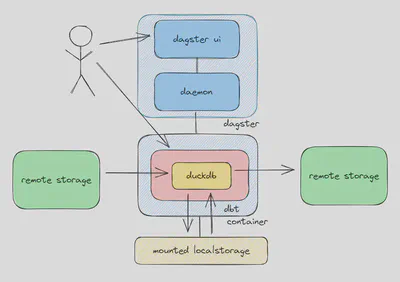
Dagster is the core of this architecture, managing the execution environment.
Dagster: A gateway to infinite possibilities
As long as your use case can be expressed in Python, Dagster’s capabilities are limitless. Dagster also seamlessly integrates with other (open-source) tools or APIs, facilitating data ingestion with airbyte and transformations with dbt. The dagster-dbt integration provides a robust method to manage and monitor dbt-driven data transformations. Nevertheless, dbt combined with Duckdb is the second most important part of our architecture, responsible for data transformation. It is important to recognize the independence between Dagster and dbt-duckdb.
In the blog we will cover:
- Structuring data layers
- Component utilization strategies
- Setup and discuss the development environment
- Architectural challenges and solutions
Cloud architectures benefit immensely from compute-storage segregation, bolstered by object storage cost-efficiency. Our proposed stack scales from a solo developer’s machine to cloud-based Kubernetes clusters. In particular, developer productivity and implementation quality are enhanced as each of the components is built with the best software engineering practices in mind.
This is different from the currently used PaaS data platforms, which are often closed-source and proprietary. We show a way how you can combine the best of both worlds for developer productivity with software engineering best practices by using the new local modern data stack and how this can be combined with PaaS platforms for a great data consumer experience.
Data layers
The rise of “Big RAM” and multicore utilization has started to eclipse “Big Data”, leading to the popularity of simple, scalable data processing engines like DuckDB, DataFusion, and Polars.
The dbt extension for DuckDB facilitates the implementation of complex pipelines and integration through a flexible plugin ecosystem.
The accompanying diagram provides a blueprint for engineers to navigate data transformation, emphasizing crucial decisions within each layer.
The diagram is a representation of a dbt project divided into three layers from left to right: source, transformations and serving layer.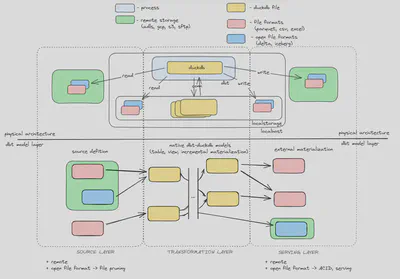
Source layer: The starting point of data pipelines encompassing local and remote data sources. It is defined as source definition.
Transformation layer: This stage sees data transformation within a DuckDB file, allowing the DuckDB engine to utilize the available resources and fully deliver optimal performance. It is defined as the dbt models.
Serving layer: The final layer where data becomes accessible to the data consumers. The data can be exported in various formats or transferred to a database server. It is defined as the dbt models with an external materialization.
Data partitioning challenge
Data naturally accumulates over time, presenting a unique set of challenges. In reality, data typically arrives in partitions (e.g., daily, monthly, or every five minutes). If partitions are processed independently, the need for complex “Big Data” tooling diminishes for most use cases.
A good partitioning strategy ensures no data is processed twice and thus pivots the problem from RAM to compute time
Despite improvements in DuckDB’s out-of-core processing, memory constraints of a single machine persist. We must adopt strategies to reduce the memory footprint, such as:
Columnar storage and data compression: The duckdb file format is highly optimized for analytics, leveraging data pruning and late materialization techniques.
Processing subsets of data: To avoid redundant transformations, it’s essential to process subsets of data incrementally and idempotently.
Dagster
Dagster as a platform backbone
Dagster should be treated as a primary component due to its:
- Role in orchestrating processing runtimes
- Operational definition of execution order and dependencies
- Governance through data lineage visualization
- Support for backfilling and reprocessing data assets
- Making the DAG as a graph of data depencies explicit and working in your favour
- Scalability across an organization through event-based lazy data asset coupling
- Dockerizaton, local execution and testing
Dagster’s built-in features support these orchestration needs, enabling rapid development and integration of new data assets within your data platform. We would recommend taking a look into great reference projects from the Dagster team:
- https://github.com/dagster-io/dagster-open-platform
- https://github.com/dagster-io/hooli-data-eng-pipelines
Dagster as partition manager
Thinking of the data partitioning challenge, Dagster’s partitioning feature enables efficient processing of data subsets. Dagster supplies partition parameters to dbt run command and offers a comprehensive view of partitioned jobs and facilitates easy backfilling - even for dependent data assets. This is even the case for nested partitions or dynamically created ones.
Dagster and dbt
The integration between Dagster and dbt is seamless, offering an orchestration layer and a metadata context for dbt projects. This integration shines when using dbt’s project variables for data partitioning.
The good Dagster-dbt integration makes partitioning very intuitive
Although the dbt project can operate standalone, Dagster’s orchestration complements dbt’s terminal-based execution. Developers can efficiently run and repeat multiple pipelines with different partitions, simulating the same behavior as in the production environment. Small and very large data volumes can easily be processed by applying this pattern of a good partitioning strategy.
dbt and DuckDB
DuckDB’s concurrency model
DuckDB breaks from the server-based concurrency model, offering an in-process OLAP system that slashes latency. The current era of ample RAM and advancements in single-machine performance make DuckDB’s approach increasingly relevant for most data use cases. DuckDB’s approach to concurrency—supporting a single writer or multiple readers—is detailed here.
dbt + DuckDB execution model
Dbt is a transformation juggernaut in data engineering, traditionally executing SQL queries on remote servers. Integrating with DuckDB, however, shifts the paradigm, placing the transformation process directly in the dbt process rather than a distant server. This fundamental change in the runtime impacts the development and data engineering workflow significantly. We will tackle its impact and explain more in the following development section.
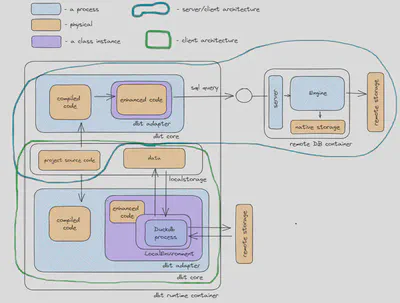
The integration of dbt with DuckDB presents many benefits from both tools:
- Analytics-friendly SQL: DuckDB’s SQL dialect is tailored for analysts, streamlining the SQL experience to resemble data frame operations.
- Duckdb extensions: For example, geospatial extensions for executing spatial joins and many more
- dbt adapter plugins: Out of the box plugins working with Excel, open table formats, databases as source, and target
- dbt’s versatility: dbt’s compatibility with various SQL dialects and templating allows for DRY SQL code and excellent data documentation — easy migration from other SQL dialects
Development
The power of local development
Software engineering has used the local environment for decades for various good reasons:
Cost-effective
Capitalized computers are cheap for companies and are there to be used. The cloud introduces development costs as operative expenses due to the consumption of rented computing time, storage, or services.
Fast feedback loop
Running programs locally makes development much faster, and the feedback loop is shorter. Do you remember the last time you were waiting for one of the PaaS providers to spin up some compute nodes? Often this takes 5-10 minutes.
Testing environment
The developer can quickly test changes locally before contributing the code to the shared repositories.
Isolated and self-contained environment
The environment can be containerized and, therefore standardized for each stage or developer.
However, different trends and new developments in the data ecosystem have changed how data pipelines are created over time. We will tackle the history of those trends and explain why the modern data stack allows us to set up the local environment again.
Before dbt
IT projects handling data have existed a long time before dbt was created. Usually, a monolithic appliance database (Oracle, SQL Server) was where developers executed their code and ran the data pipelines. Local deployments and testing were easy because each database had a light version that could run locally on the developer’s machine, enjoying all the benefits of local productivity. However, other problems, such as observability, lineage and version control for data assets were paramount. These could be solved later with the introduction of dbt.
What changed over time?
Separation of compute and storage
The development of the Hadoop ecosystem and later Spark and cheap remote storage popularised scaling compute and storage separately to best fit individual needs. As a result, teams can quickly spin up new compute instances query and transform the data on the remote storage.
Remote storage and open table formats
Advances in analytical file formats and the proliferation of cloud storage solutions, such as S3 and similar services, have revolutionized data storage. Open table formats like Delta and Iceberg have risen, logically grouping files into a single table and pushing table metadata toward remote storage. Delta’s whitepaper and T-Mobile’s blog: Why we migrated to a Data Lakehouse on Delta Lake elucidate the shift toward remote storage and open table formats. The industry trend is evident with Microsoft Fabric’s adoption of Delta and the support of modern query engines for Iceberg.
PaaS data platform
Modern data platforms are usually fully featured distributed environments that make a living of providing one uniform data platform that automates complex infrastructure management.
Complexity of the PaaS platform. What if it was simpler locally?
They bring a lot of good out-of-the-box features like RBAC, notebook experience, and integration of visualization tools. But at the same time add an unnecessary overhead for the data transformation.
Current dbt development practice
Platforms like Snowflake and Databricks have shifted development from local environments to a cloud-based model. As a result, the need emerged to develop a transformation framework (dbt) that allows for remote execution, providing the best software engineering practices.
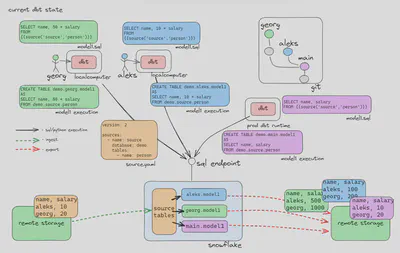
The following diagram illustrates the current dbt development process. Imagine that we have the data in the remote storage with names and salaries. This data can be either ingested as the managed table or we can create an external table definition. Either way, the table is defined as the source definition in the source.yaml file depicted with the orange color. The developer’s task is to change the calculation for the new salary. Each developer has their own unique environment. It is their own branch and implementation for the dbt project depicted in an individual color per developer. The model1.sql contains the current changes on the respective branch and model1 execution represents the code that would be sent and executed on the transformation engine. Note that the execution code contains SQL code change from the current branch and the developer-specific schema which is defined in the profiles.yaml file
PaaS problems for data transformation pipelines
Normally, the server-side component of the PaaS data platform (their big data engine and custom extensions) are closed-source. Therefore, a local (possibly neatly containerized) replication and simulation of the production environment is not possible. As a result, the code has to be tested and executed in a remote environment. Due to the forced remote development, the feedback loop is reasonably slower and introduces additional development costs.
A developer machine has more power than the smallest development cluster in a PaaS. It is already capitalized - no extra cost needs to be paid for using it.
Developers often copy the code from a source package into a remote notebook for debugging purposes or have to deploy code to the platform to test an E2E data pipeline with the orchestrator.
Changes towards new development
Computer improvements
Over time, computers got better in each aspect. Nowadays, computers can efficiently process gigabytes of data and run multiple docker images at a time.
In memory OLAP systems
The incredible development of the in-memory OLAP system in the last few years and the introduction of the Apache Arrow format changed the data landscape and interoperability between different engines.
Duckdb: TCPH S100 ~ 600 million rows in 152 seconds with 32 cores
State of the union for #Python OLAP Database#Hyper ; #DuckDB ; #Datafusion and #Databend
— Mim (@mim_djo) November 21, 2023
all running inside #Fabric Notebook pic.twitter.com/VDzN2mMnz8
This doesn’t mean that we can run everything at once. But with smart partitioning and processing a chunk at a time, we can reasonably quickly achieve the desired data transformation
Open file format library independent of big data engines
Generally, open table formats such as delta or iceberg were developed to serve the big data engines, such as spark or flink. Parts of their codebase are closely coupled with their execution engines. Because of that, developers would be forced to use spark and run JVM to interact with the open table formats.
This has changed recently: The open file format is a protocol and not a specific implementation. This means that you can implement an interface in a native library - often written in Rust - that can be used to interact with the open table format without the need for a clunky big data framework. The delta-rs serves as such an implementation, making Python bindings very easy to implement. It eliminates the need for the JVM or the strong coupling to a distributed execution engine. It was born with the need to read kafka topics and write the data directly to delta tables in S3. Employing that approach was making this process more cost-effective and reliable than a big data engine (Spark).
A spark cluster is not needed anymore to copy data from kafka topic to S3 delta table
Iceberg is offering a native implementation as well: iceberg-python.
New “old” Dagster + dbt + DuckDB development practice
The reasons above and the convergence of dbt and DuckDB transforms data processing and recalibrates the development practices for data. It brings software engineering best practices back to the domain of data processing and makes local development possible again - and easy.
In this setup, our goal is to have:
- Uniform data sources for developers: Ensuring every developer can access the same data as the source of the transformation.
- Isolated local development: Each developer has its isolated development environment integrated with the git branching
- Streamlined staging and deployment processes: Implementing common branches for staging and deployment best practices.
Uniform data source for developers
Each developer should be able to pull the same data into the transformation process quickly. This means the dbt-duckdb has to be able to pull the data automatically from the remote storage. With dbt-duckdb, there are several great out-of-box possibilities to access remote data:
Duckdb and remote files: DuckDB has a native way to access remote files with the httpfs or filesystem extension. You can define it easily in the dbt-duckdb source configuration.
dbt-duckdb plugins: Plugins in the dbt-duckdb are an extension to the dbt adapter, which allows us to extend the reading and writing capabilities of the dbt-duckdb process. There is a plugin to read Excel files or open table formats, such as iceberg or delta.
Gobally accessible URIs for data (i.e. S3 buckets) allow to run transformation locally
For instance, the delta plugin uses the delta-rs package, which enables reading directly from different cloud object stores. Using delta and dbt-duckdb is simple. You can find an example project with a sample configuration here.
Further new plugins can be implemented easily. In case one is missing, feel free to open an issue and connect in the dbt Slack.
Isolated local development
The problem of working isolated on a database server was complicated. A solution was introduced with dbt - as we showed before in the visualization about the current state of data development. Being able to develop independently from others and knowing that changes do not interfere with each other is very important for developer productivity. One main idea of the new local stack is to introduce changes in the local environment. Once each developer has tested locally in their own environment changes move up to shared and closer to production environment.
Streamlined staging and deployment processes
A cookbook recipe to define an environment, including its state, is crucial for smooth transitions from development to production. This is the basis of ensuring that a development and production environment are the same and will not introduce problems due to different environments. With the same environment, you can test and ensure the same behavior across different deployment pipeline stages.
Containerized pipelines streamline deployment & testability
We can easily containerize the whole orchestration and transformation pipeline. which means that the developer can easily ensure the exact runtime for the various development, test, and prod environments.
The new better development practice
Considering the above points, we suggest a potential implementation of the current state-of-the-art development guidelines for data transformation pipelines.
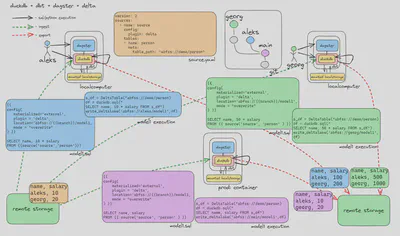
The diagram shows each developer has a local containerized instance of the entire stack. The developer can start the process using the Dagster UI or the dbt CLI. The running process pulls the data from the source definition model and transforms it to the desired state. The source definition is defined in the source.yaml file. If the model is an external materialization, the process pushes the data to remote storage, further serving the data consumers. The model is defined in the model1.sql and the code which runs is illustrated in the model execution. When the transformation code lands in the main branch, the CI/CD agent can first run the tests and push the code to the production environment.
We use the newly developed and experimental delta plugin in the diagram, but the concept is the same for all plugins.
Cost reduction
As the business evolves and moves from strategic reporting (refresh 1x/Day) towards near real-time products (15 minutes, 5 minutes, streaming) the PaaS products can get very expensive. Moving the transformation logic into a containerized environment can reduce operational costs which are introduced due to the PaaS platform and resolve the vendor lock-in problem.
Synergy of the PaaS and modern data stack
We don’t think that the modern data stack and the PaaS data platform are opponents. They can be the perfect mix if combined in the right ways.
Platform as an implementation detail and component
In particular, the PaaS should become an implementation detail and part of the data platform and not be the single one-stop-shop solution for everything.
The modern data stack advantages:
- ✅ Lower operational and development cost for the transformation
- ✅ Better software engineering practices
- ✅ Better orchestration features
The advantages of PaaS systems:
- ✅ Better data consumer experience
- ✅ Synergy with the enterprise visualization tools
- ✅ Mature RBAC and enterprise features
Challenges of DuckDB + dbt
Debugging and analyzing production DuckDB files
One critical area is establishing effective methods for debugging and analyzing DuckDB files in a production environment. Troubleshooting and understanding production data is vital for maintaining system reliability and performance.
The problem is the absence of a built-in server that facilitates access control and handles concurrency for multiple users. This problem can be compensated with specific tooling, which we will discuss in the next section, but the overall duckdb concurrency problem still holds. We want to explore and discuss better solutions to this problem in the future.
Missing RBAC
We proposed above to use DuckDB in a stateless (transformation only) mode. There is not neccessarily a need for access control directly on the side of DuckDB. However, the adjacent layers of the stack then need implement these control measures:
Object store: File-based permission management from the storage layer.
Serving layer: The serving layer can implement fine-grained data access control means (row/column) masking and filtering.
The usage patterns can also be divided into groups:
Creators (Developers): The only way to control the access is on the source side with the Object store permissions.
Data consumers: As outlined above, this problem can be the source of great synergy with the PaaS if used correctly. For example, we can push ready data to Microsoft Fabric or use a delta share server to control RBAC.
Tooling
Accessing remote DuckDB files and debugging is part of the developer workflow. The tooling is not as mature as traditional workflows but is improving daily. We have explored the following options:
- dbt power user VSCode extension
- ✅ Locks the file only during the execution of queries.
- ❌ Has difficulty refreshing environment variables.
- ❌ It is not intuitive for the nondevelopers.
- DuckDB CLI
- ✅ Offers quick setup and supports tab completion.
- ❌ Lacks a graphical interface, operating solely as a terminal application.
- Buenavista server, compatible with Presto and PostgreSQL dialects,
enables server-side DuckDB management
- ✅ which is particularly advantageous for concurrency control. Moreover, conventional JDBC tools like DBeaver or Jetbrains DataGrip can connect to this server setup.
- ❌ It is still a very new software project
Serving layer
The last layer in our transformation process is the serving layer. The dbt process exports the data to the storage; from there on, it is served and further integrated:
Serving with an API server
Three options for serving the data as an API server:
- Delta Sharing: Provides an API server layer on top of the delta tables
- ROAPI: Generic API server that can be used to serve data from various formats
- Cube.dev: Offers caching and a semantic-layer functionality but doesn’t work with the files directly
Dagster integration
Having Dagster as a core part of the pipeline, arbitrary connections and integrations can be easily added. For example:
- Export data to Excel and send the file by email.
- Pushing data to a BI tool like Tableau Server for advanced visualization and analytics.
Using PaaS as a serving layer
The PaaS platforms have outstanding data analytics integration and data-consumer interaction features. They also offer great BI integrations such as:
- PowerBI connects natively to Fabric, providing state-of-the-art integration and access control
- Almost every enterprise BI tool has good integration with big PaaS data platforms such as Databricks and Snowflake
By combining the best of both worlds developer productivity and data consumer experience can be great.
Conclusion
As the data ecosystem rapidly evolves, we must stay adaptive, seeking superior, simpler, and more cost-effective methodologies. Improved in-memory OLAP systems, faster remote storage, open file formats, and the new dbt-duckdb execution runtime allow us to introduce a new way of developing and executing data transformation pipelines supported by software engineering best practices. This blog juxtaposes the traditional development state with fresh opportunities afforded by technological advances, advocating for a balanced approach that leverages both the modern data stack and PaaS platforms.
Interestingly, the need for simplification is not unique to the transformation layer: For the ingestion of data, recently Dagster embedded ELT proposed a complementrary model based on similar values.
We are very excited about the data ecosystem’s future and how the new modern local stack evolves and supports that journey along the way.
We are happy to discuss our blog with you, so dont hesitate to write us:
- You can contact us in the contact formular or dbt slack in the #db-duckdb channel
- Comment here in the blog
- Reach out to the authors directly
Both authors thank the reviewers of the blog for their valuable feedback and input.
A sample project demonstrating the interaction of dbt with DuckDB and external delta files is found here.
The image was created using Firefly by Adobe. Parts of this text were adeptly generated by ChatGPT but enhanced by real humans.