SFTP sensor

Welcome 😄 to this blog series about the modern data stack ecosystem.
post series overview
This is the 7th and so far the last part of this series of blog posts about the modern data stack. It is an example of how to use sensors and trigger new runs of a data pipeline when a file arrives in a directory available via SFTP.
This example is based on https://github.com/dagster-io/dagster/issues/6978.
The other posts in this series:
- overview about this whole series including code and dependency setup
- basic introduction (from hello-world to simple pipelines)
- assets: turning the data pipeline inside out using software-defined-assets to focus on the things we care about: the curated assets of data and not intermediate transformations
- a more fully-fledged example integrating multiple components including resources, an API as well as DBT
- integrating jupyter notebooks into the data pipeline using dagstermill
- working on scalable data pipelines with pyspark
- ingesting data from foreign sources using Airbyte connectors
- SFTP sensor reacting to new files
reacting to new files in a directory
Especially in an enterprise context, files are all too often shared via almost ubiquitous FTP servers. Even a data pipeline following the principles of the modern data stack (which often uses data assets defined by DBT using SQL in a cloud data warehouse) needs to interface with these data sources.
Sensors allow you to instigate runs based on any external state change.
An example:
- The operation: A filename specified from the configuration is logged to the console.
@op(config_schema={"filename": str})
def process_file(context):
filename = context.op_config["filename"]
context.log.info(filename)
- The sensor:
@sensor(job=log_file_job, default_status=DefaultSensorStatus.RUNNING)
def my_directory_sensor():
for filename in os.listdir(MY_DIRECTORY):
filepath = os.path.join(MY_DIRECTORY, filename)
if os.path.isfile(filepath):
yield RunRequest(
run_key=filename,
run_config={
"ops": {"process_file": {"config": {"filename": filename}}}
},
)
- Triggering the sensor: By default, dagster checks every sensor for updates approximately every 30 seconds.
cd MY_DIRECTORY # step into the dummy directory created from launching the sensor
# genrate some dummy files
touch foo
touch bar_some_file
After a couple of seconds, you should be able to view the triggered RunRequests of the sensor:

In dagit you can observe the logs of the sensor:
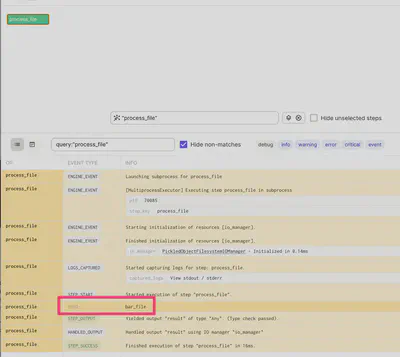
A sensor defines an evaluation function that returns either:
- One or more `RunRequest` objects. Each run request launches a run.
An optional `SkipReason` specifies a message that describes why no runs were requested.
When a run_key is specified in a RunRequest the central dagster database can guarantee to trigger the job once - and only exactly once.
This allows avoiding creating duplicate runs for your events.
In case you are operating with high-volume events using a Cursor might be more efficient.
Further details about working with a Sensor are found in the dagster documentation.
SFTP Sensor example
Now for a real SFTP-based example: a docker-compose file is available here to bring up a dummy SFTP server. You can start it using:
docker-compose up
To validate that the SSH port of the SFTP server is up and running try to establish an SSH session with:
ssh foo@127.0.0.1 -p 2222
# password: bar
you will need to accept the host key
Create at least some dummy files in the directory which is served by the SFTP server:
touch foo-bar-baz
Now, validate that the dummy SFTP server is serving these files. You can use the command line if you prefer or any GUI-based FTP tool like Cyberduck or Filezilla or any other.
To connect to the dummy SFTP Server from python we follow along with a great example: https://gist.github.com/lkluft/ddda28208f7658d93f8238ad88bd45f2
import os
import re
import stat
import tempfile
import paramiko
def paramiko_glob(path, pattern, sftp):
"""Search recursively for files matching a given pattern.
Parameters:
path (str): Path to directory on remote machine.
pattern (str): Python re [0] pattern for filenames.
sftp (SFTPClient): paramiko SFTPClient.
[0] https://docs.python.org/2/library/re.html
"""
p = re.compile(pattern)
root = sftp.listdir(path)
file_list = []
# Loop over all entries in given path...
for f in (os.path.join(path, entry) for entry in root):
f_stat = sftp.stat(f)
# ... if it is a directory call paramiko_glob recursively.
if stat.S_ISDIR(f_stat.st_mode):
file_list += paramiko_glob(f, pattern, sftp)
# ... if it is a file, check the name pattern and append it to file_list.
elif p.match(f):
file_list.append(f)
return file_list
# Setup paramiko connection.
ssh = paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh.connect('localhost', port=2222, username='foo', password='bar')
sftp = ssh.open_sftp()
# Actucal call of paramiko_glob.
files = paramiko_glob('upload/', '', sftp)
print(files)
sftp.close()
ssh.close()
To build a sensor with support for remote files, we adapt the existing minimal dummy sensor to:
# file_list.append(f)
# is replaced with:
file_list.append(RunRequest(
run_key=f,
run_config={
"ops": {"process_file": {"config": {"filename": f}}}
},
))
# Actucal call of paramiko_glob.
yield from paramiko_glob('upload/', '', sftp)
As you can observe, only minor changes are necessary to interact with the generator properly.
https://docs.dagster.io/_apidocs/libraries/dagster-ssh#ssh-sftp-dagster-ssh might be a helpful utility for such cases.
Furthermore, in case backfilling of an upstream updated source file needs to be performed:
ops:
process_file:
config:
filename: "upload/myfile.parquet/dt=2022-01-01.parquet"
Simply pass the same file key a second time via the Launchpard - or in case you configured a partitioned run - you could quickly launch a backfill task for this asset.
You can find a much more comprehensive example on how to use SFTP (including spark, duckdb and DBT) here: https://github.com/geoHeil/dagster-ssh-demo.
summary
Sensors allow dagster to kick-off orchestration of a data pipeline based on external state changes of source systems.
Asset sensors in particular allow to create a sensor that checks for new AssetMaterialization events for an asset key - and launch the downstream data dependencies.
This enables cross-job and even cross-repository and thus cross-team dependencies whilst still maintaining data lineage and observability. Each job run instigated by an asset sensor is agnostic to the job that caused it.